在当今数字化浪潮中,微服务架构已成为构建复杂、可扩展应用的主流范式。它将单体应用拆分为一组松耦合、独立部署的小型服务,每个服务专注于单一业务功能。随着服务数量的增加,服务间的通信与数据流转变得日益复杂。这时,消息中间件应运而生,成为微服务架构的“神经系统”,而Apache Kafka则是这一领域的佼佼者。本文将深入详解Kafka,并探讨其在信息系统集成服务中的核心价值与实践。
一、消息中间件与微服务:解耦与异步的基石
微服务架构的核心挑战之一是实现服务间的高效、可靠通信,同时保持服务的独立性与弹性。传统的同步调用(如HTTP/REST)容易导致服务耦合,并在调用链中出现单点故障与性能瓶颈。消息中间件通过引入异步、基于消息的通信模式,完美解决了这些问题:
- 解耦:生产者和消费者无需知晓对方的存在,只需与消息队列交互,降低了服务间的直接依赖。
- 异步:生产者发送消息后无需等待消费者处理,提高了系统的响应速度和吞吐量。
- 削峰填谷:能缓冲瞬时流量高峰,避免后端服务被压垮。
- 可靠性:提供消息持久化、确认机制,确保消息不丢失。
在众多消息中间件中,Kafka凭借其独特的架构设计脱颖而出,不仅是一个消息队列,更是一个高吞吐、分布式、可持久化的流数据平台。
二、Apache Kafka 核心架构详解
Kafka的设计哲学围绕“日志”概念展开,其核心组件与概念如下:
- 基本概念
- Topic(主题):消息的逻辑分类,生产者向特定Topic发布消息,消费者订阅Topic消费消息。
- Partition(分区):每个Topic可以被分为多个分区,分布在不同的Broker上。分区是Kafka实现水平扩展和并行处理的基础。消息在分区内有序存储,并分配一个递增的偏移量(Offset)。
- Producer(生产者):向Kafka的Topic发布消息的客户端。
- Consumer(消费者):从Topic订阅并处理消息的客户端。消费者以消费者组(Consumer Group)的形式工作,组内消费者协同消费一个Topic的所有分区,实现负载均衡。
- Broker:Kafka集群中的单个服务器节点,负责消息的存储和转发。
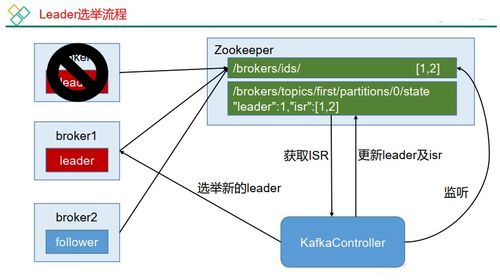
- ZooKeeper:在早期版本中,Kafka依赖ZooKeeper进行元数据管理和集群协调(如Broker状态、Topic配置、消费者偏移量)。新版本(KIP-500)正致力于移除对ZooKeeper的依赖,实现更简化的架构。
- 核心优势
- 高吞吐与低延迟:基于顺序I/O和零拷贝技术,能轻松处理每秒数百万条消息。
- 可扩展性:通过增加Broker和分区,可以线性扩展存储容量和处理能力。
- 持久化与高可用:消息持久化到磁盘,并支持多副本(Replication)机制,确保数据安全。
- 流处理能力:不仅用于消息传递,其内置的Kafka Streams库及与Flink、Spark等流处理框架的深度集成,使其成为实时流处理应用的理想平台。
三、Kafka在信息系统集成服务中的关键应用场景
信息系统集成服务旨在将企业内部及跨企业的异构系统、应用和数据连接起来,实现业务流程自动化与数据共享。Kafka在其中扮演着“中央数据总线”的角色,以下是其典型应用:
- 实时数据管道:构建企业级实时数据流。例如,将来自ERP、CRM、网站点击流、IoT设备的数据实时采集到Kafka,再统一分发给数据仓库、实时分析仪表盘或机器学习模型,为决策提供即时洞察。
- 事件驱动架构(EDA)集成:当核心业务系统(如订单系统)状态变更时(如“订单已创建”),将其作为事件发布到Kafka。其他订阅该事件的系统(如库存系统、物流系统、推送服务)可异步接收并触发自身业务流程,实现松耦合、敏捷的业务集成。
- 日志聚合与监控:收集所有微服务、服务器和应用产生的日志,统一推送至Kafka。下游可以连接日志分析系统(如ELK Stack)进行集中查询、分析和异常告警,极大提升运维效率。
- 数据变更捕获(CDC):通过连接器(如Debezium)监控数据库的Binlog,将数据的插入、更新、删除操作实时捕获为事件流写入Kafka。这为数据同步、缓存更新(如更新Redis)、构建查询视图提供了极佳的数据源。
- 微服务间的异步通信:作为微服务间的通信骨干,替代大量的点对点HTTP调用。服务通过发布/订阅事件进行通信,提高了系统的整体容错性和可伸缩性。
四、实施考量与最佳实践
在信息系统集成中引入Kafka时,需注意:
- 拓扑规划:合理设计Topic、分区数和副本因子,平衡性能与资源。
- 数据格式:采用通用的序列化格式(如Avro、Protobuf,并配合Schema Registry使用),确保数据兼容性和演进能力。
- 连接器生态:充分利用Kafka Connect框架及其丰富的连接器(连接数据库、消息队列、云服务等),减少自定义开发成本。
- 运维监控:建立完善的监控体系,关注集群健康度、吞吐量、延迟和积压情况。
- 安全与治理:实施认证、授权、加密,并建立清晰的数据血缘和生命周期管理策略。
###
Apache Kafka已从最初的消息队列演变为现代企业不可或缺的实时流数据平台。在微服务架构和复杂的信息系统集成服务中,它通过提供高可靠、高吞吐的异步通信和数据流转能力,有效地解耦了系统组件,支撑了实时业务与数据分析。理解和掌握Kafka,对于构建敏捷、健壮、面向未来的数字化集成体系至关重要。将其作为企业信息流的中枢,无疑是驱动业务创新与高效运营的关键一步。